
本記事で紹介したいこと:
Excelのグラフやピボットテーブルを利用して過去データから先月の売上高や来店者数の要因分析を行うことができます。これは、BI(ビジネスインテリジェンス)と呼ばれるデータ分析手法です。これに対して、過去データの傾向やパターンからモデルを作成して来月の売上高や来店者数を予測することができます。これは、AI(人工知能)によるデータ分析と呼ばれます。AIによるデータ分析を行うには、Pythonコードや専用ツールが必要と思われるかもしれませんが、いくつかの制約はあるものの、Excelでも可能です。今回は、ExcelとRapidMiner Studioによる米国マサチューセッツ州ボストン地区の住宅価格の予測を行います。
目次 Table of Contents
BIとAIによるデータ分析の違い
BIとAIによるデータ分析の違いを比較表にまとめてみました。BIは、主にExcelなどを使って過去~現在のデータを対象とした要因分析を行います。一方、AIは過去~現在のデータをもとに将来の予測を行います。なお、過去データの分析は、AIで作成するモデルの精度や品質を高めるために重要なステップとなります。
| BI(ビジネスインテリジェンス) | AI(人工知能) | |
|---|---|---|
| 目的 | 過去データを様々な角度から可視化して傾向やパターンを発見、結果に対する要因分析を行う | 過去データの傾向やパターンからモデルを作成、そのモデルを使って予測を行う |
| 対象データ | 過去~現在 | 過去~現在、未来 |
| 分析手法 | Excelのグラフやピボットテーブルなど | 機械学習(教師あり学習/教師なし学習)、深層学習 |
| 主な用途 | 先月の売上高や来店者数の要因分析 過去にクーポンに反応した人の傾向 | 来月の売上高や来店者数の予測 クーポンに反応しやすい人のターゲティング |
Excelによる住宅価格の予測
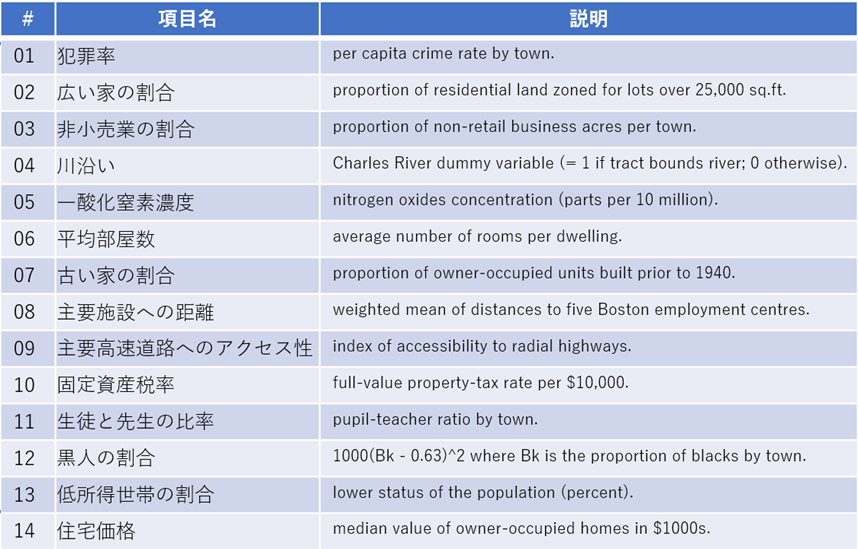
Excelのデータ分析ツールの1つである「回帰分析」を利用して数値の予測と予測結果に影響を与えた要因を分析します。前者を「数値予測」、後者を「要因分析」と呼ぶことにします。予測したい数値項目を「目的変数」、目的変数に関連する数値項目を「説明変数」と呼びます。要因分析では、どの説明変数が目的変数に影響を与えたかを定量的に確認します。また、説明変数が1つのものを「単回帰分析」、説明変数が複数のものを「分析」と呼びます。今回は、住宅価格の予測を行いますので「重回帰分析」です。目的変数として住宅価格を予測するため13個の説明変数を利用します。データの形式は以下の通りです。
・利用するデータ:Boston Housing データセット(The Boston House-price data)
2-1. Excelで回帰分析を行う準備
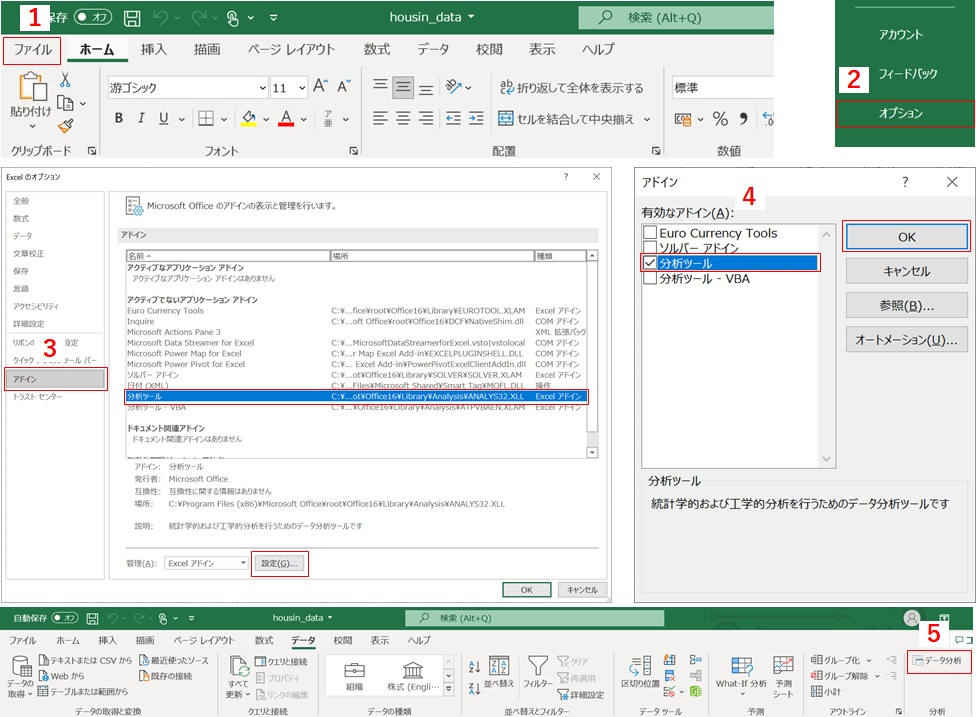
Excelで回帰分析を行うには、分析ツールを使用します。デフォルトでは、分析ツールが有効になっていません。以下の手順にしたがって有効にしてください。
①「ファイル」メニューを選択する
②「オプション」を選択する
③「Excelのオプション」ダイアログボックスの「アドイン」、「分析ツール」を選択して「設定」ボタンを押す
④「アドイン」ダイアログボックスの「分析ツール」をチェックして「OK」ボタンを押す
⑤「データ」メニューを選択すると、一番右に「データ分析」が表示される
2-2. Excelで回帰分析を実行する
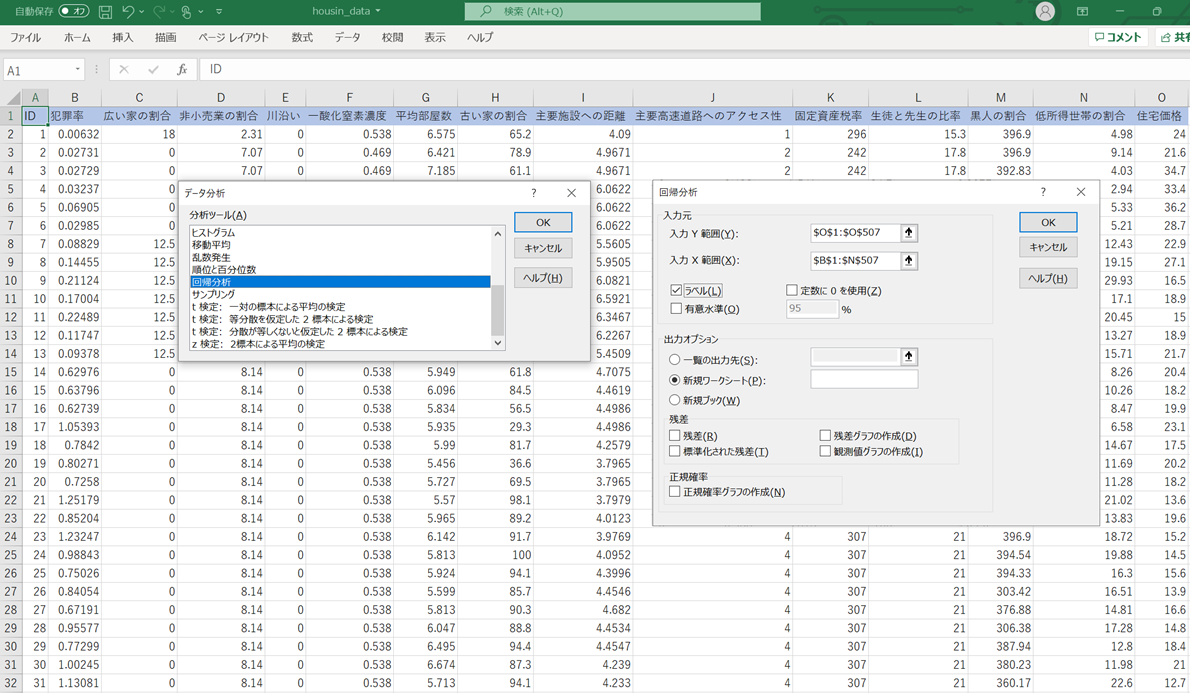
回帰分析を実行する手順は、以下のとおりです。
①「データ」メニューから「データ分析」を選択する
②「データ分析」ダイアログボックスの「分析ツール」から「回帰分析」を選択して「OK」ボタンを押す
③「回帰分析」の設定ダイアログボックスで表示されるので、以下のように設定を行う
-入力Y範囲(Y):住宅価格のセル(O1~O507)
-入力X範囲(X):犯罪率~低所得世帯の割合のセル(B1~N507
-ラベル(L):入力Y範囲(Y)と入力X範囲(X)にタイトル行を含めて範囲選択したので、チェックする
-出力オプション:新規ワークシートをチェックする(結果が見やすいため)
2-3. Excelの回帰分析実行結果
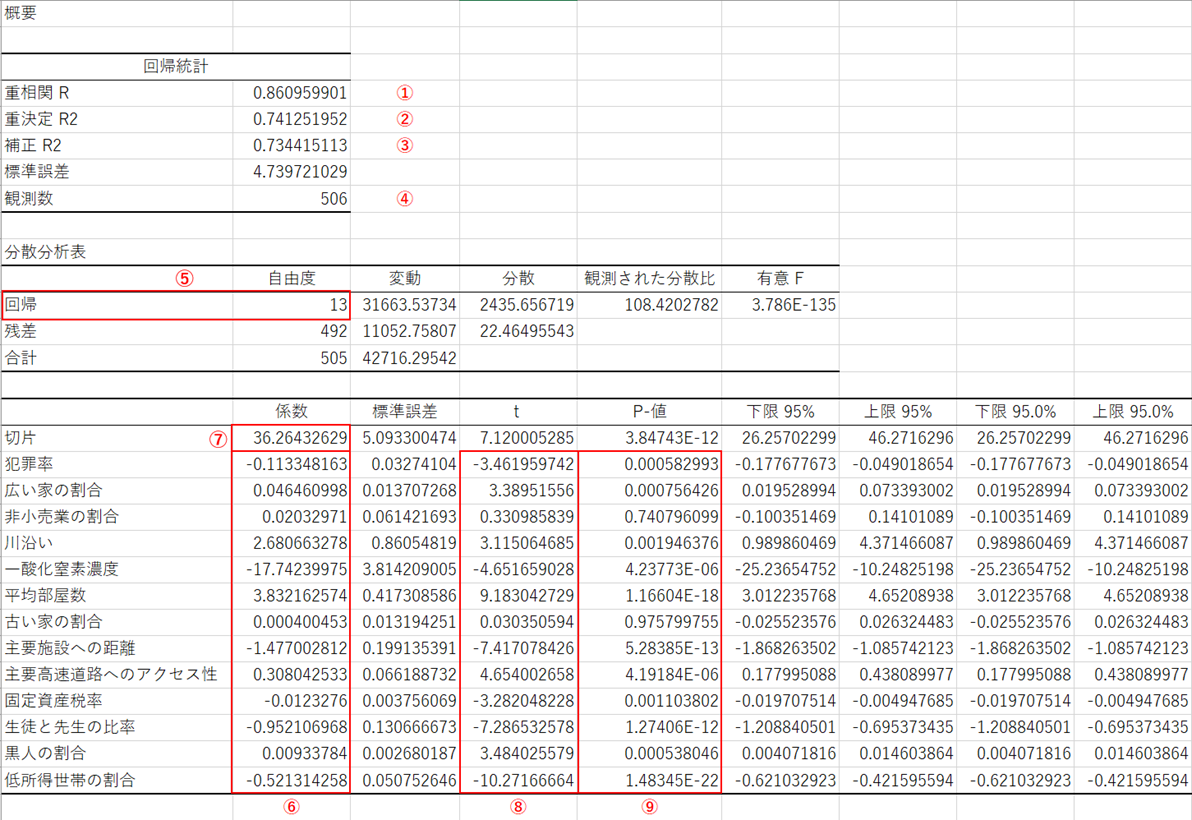
回帰分析の実行結果について、特に住宅価格の予測と要因分析に役立つ箇所の説明を行います。
① 重相関係数:0~1の間の値、1に近いほど良い、目的変数と予測値との相関係数 (重相関係数≧0.7が良い)
② 決定係数(寄与率):0~1の間の値、1に近いほど良い、説明変数によって目的変数がどの程度説明できているかを表す(決定係数≧0.5が良い)
③ 補正R2:自由度調整済決定係数とも呼ばれる、①と②は説明変数の個数の影響を受けるので、この影響を取り除いた指標 (補正R2≧0.7が良い、補正R2≧0.8が非常に良い)
④ 観測数:データ行数
⑤ 回帰の自由度:説明変数の個数
⑥ 回帰係数(偏回帰係数):各説明変数が1単位変化したときに住宅価格に与える影響を表す(例:平均部屋数が1つ増えると住宅価格が3.83増える)
⑦ 切片:全ての説明変数の値が0(ゼロ)のときの目的変数(住宅価格)の値を表す
⑧ t値:目的変数(住宅価格)に対する説明変数の影響度を表す
⑨ P値:説明変数を回帰式に採用したときの危険率を表す(Pは、Provability(確率)の頭文字)
2-4. Excelによる住宅価格の予測
住宅価格の予測を行うには、回帰分析の実行結果の切片と回帰係数を使って回帰式を作ります。説明変数が複数ある回帰式は、以下のように一般化して表します。
・y = a + (b1*x1) + (b2*x2) +・・・+ (bi*xi)
– y:目的変数(住宅価格)
– a:切片
– b1:1番目の説明変数の回帰係数
– x1:1番目の説明変数の値
– b2:2番目の説明変数の回帰係数
– x2:2番目の説明変数の値
– bi:最後の説明変数の回帰係数
– xi:最後の説明変数の値
下図の回帰式と1レコード目の説明変数の値を使って住宅価格を予測すると29.98となりました。実際の住宅価格が24.0なので、その差がプラス4.98でした。
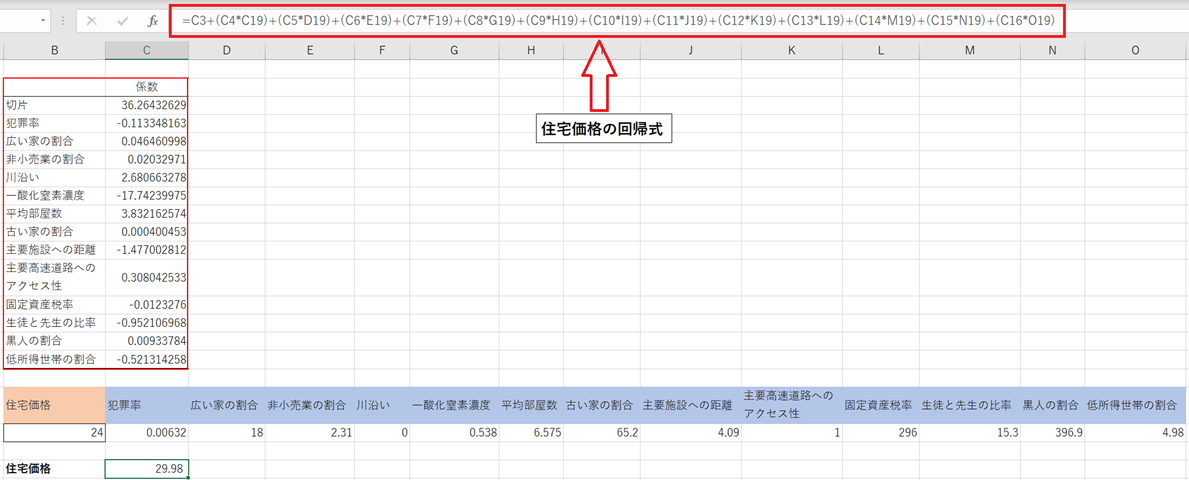
2-5. 住宅価格に影響している要因分析
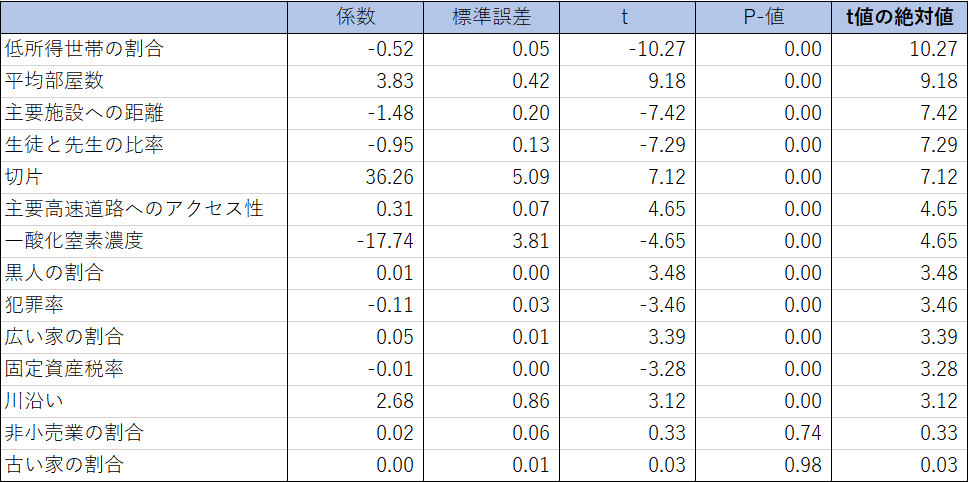
回帰分析の実行結果から、どの説明変数が目的変数(住宅価格)に影響しているか(影響度)を確認します。影響度は、t値の絶対値を使って判断します。説明変数のt値の絶対値に比例して目的変数への影響度が大きくなると判断します。t値の絶対値から影響度が最も大きいものが「低所得世帯の割合」、影響度が最も小さいものが「古い家の割合」という結果が得られました。
RapidMiner Studioによる住宅価格の予測
Rapidminer Studioを利用して住宅価格の予測を行います。使用するアルゴリズムは、GLM(Generalized Linear Model、一般化線形モデル)です。GLMは、説明変数の予測結果への影響が回帰係数で示されるのでホワイトボックスモデルと呼ばれます。
・利用するデータ:Boston Housing データセット(The Boston house-price data)
・Rapidminer Studio v10.0(フリー版)
・使用するアルゴリズム:Generalized Linear Model
・Rapidminer Extension(拡張機能):Generate Interpretation(0.6.000)
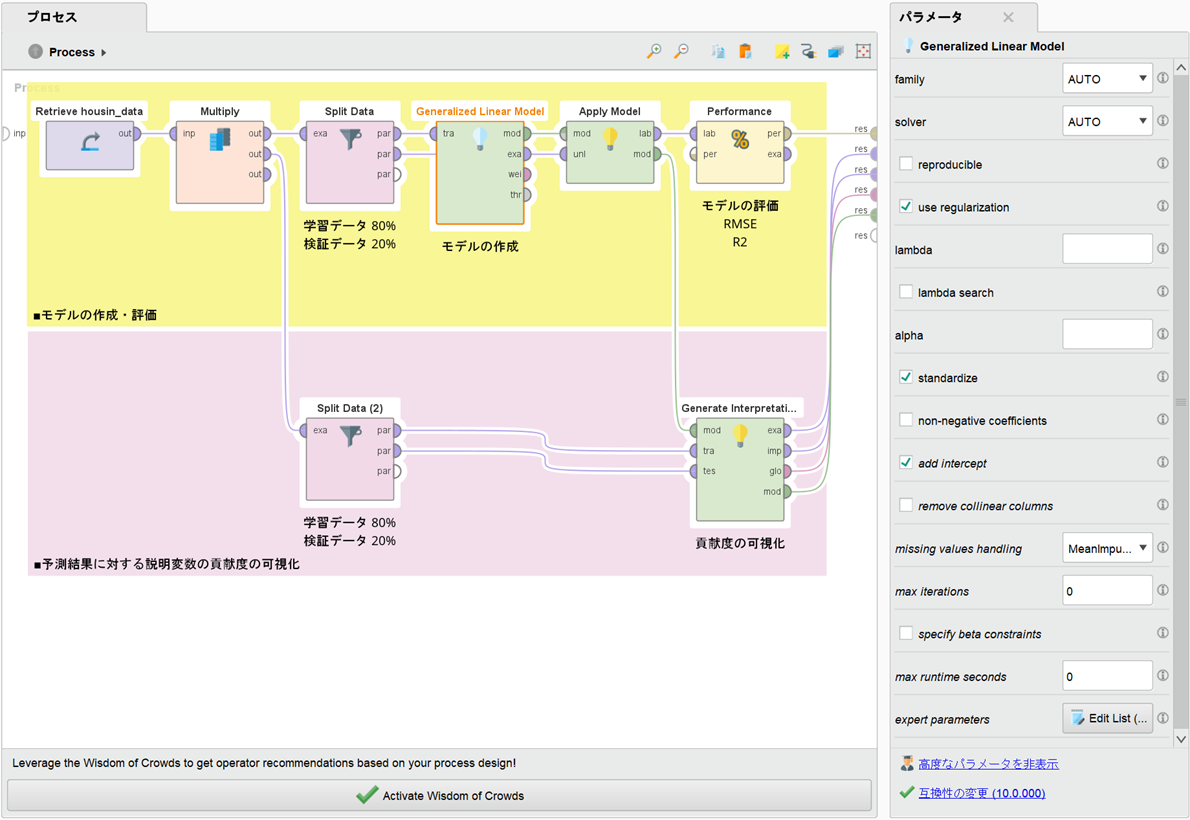
3-1. RapidMinerのプロセス
RapidMinerのプロセスは、2つのパートに分かれます。上段は、GLMを利用して住宅価格の予測モデルを作成、モデル精度を二乗平均平方根誤差RMSE(Root Mean Squared Error)と決定係数R2(squared correlation)で評価します。下段は、Generate Interpretationを利用して予測結果に対する各説明変数の貢献度を可視化します。上段、下段とも全体の80%を学習データ、20%を検証データとして使用します。データ分割は、stratified sampling(層化抽出法)によって行います。
・GLMのパラメータ(上段)
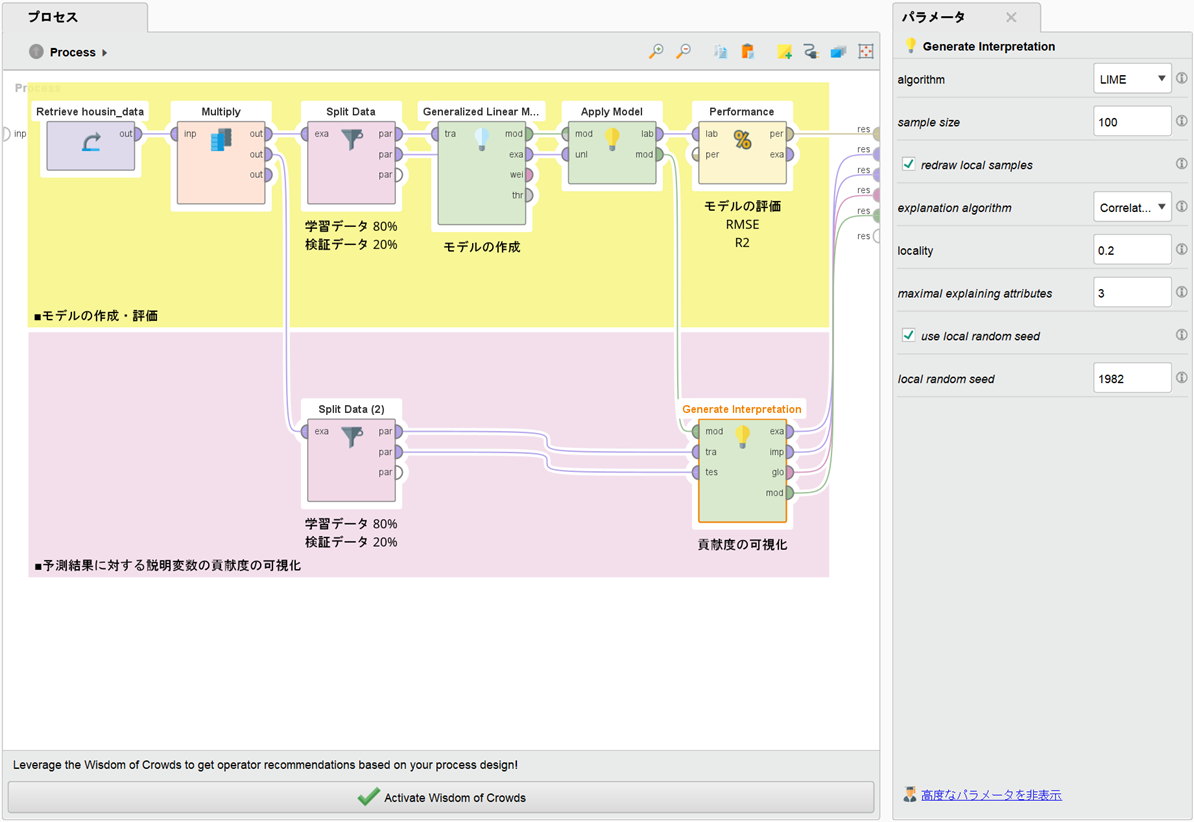
・Generate Interpretationのパラメータ(下段)
3-2. モデルの評価
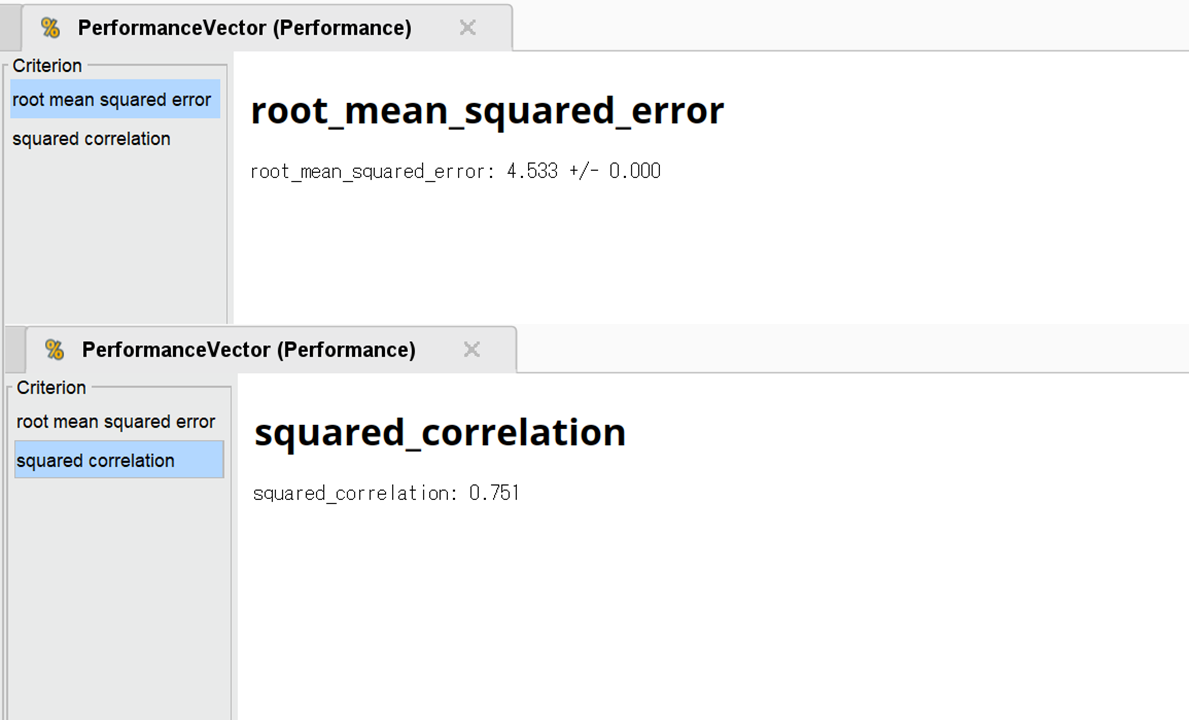
・モデルの精度
モデルの精度をRMSEとR2で確認します。RMSEが4.533、R2が0.751なので比較的精度の良いモデルと言えます。なお、RMSEとR2の概要は、以下のとおりです。
RMSE:
– 実測値と予測値の平均的な予測誤差を表す
– 値が小さい程、予測精度が高いモデル(目的変数と予測値の誤差の平均なので、データや目的に合せて目安を決める)
– 予測誤差を2乗するので外れ値の影響を受けやすい
R2:
– 平均値では説明できなかったバラツキのうち、どの程度モデルの予測によって説明できるかを表す
– 値が大きい程、予測精度が高いモデル(R2≧0.5が良い)
– 0~1の間の値をとる
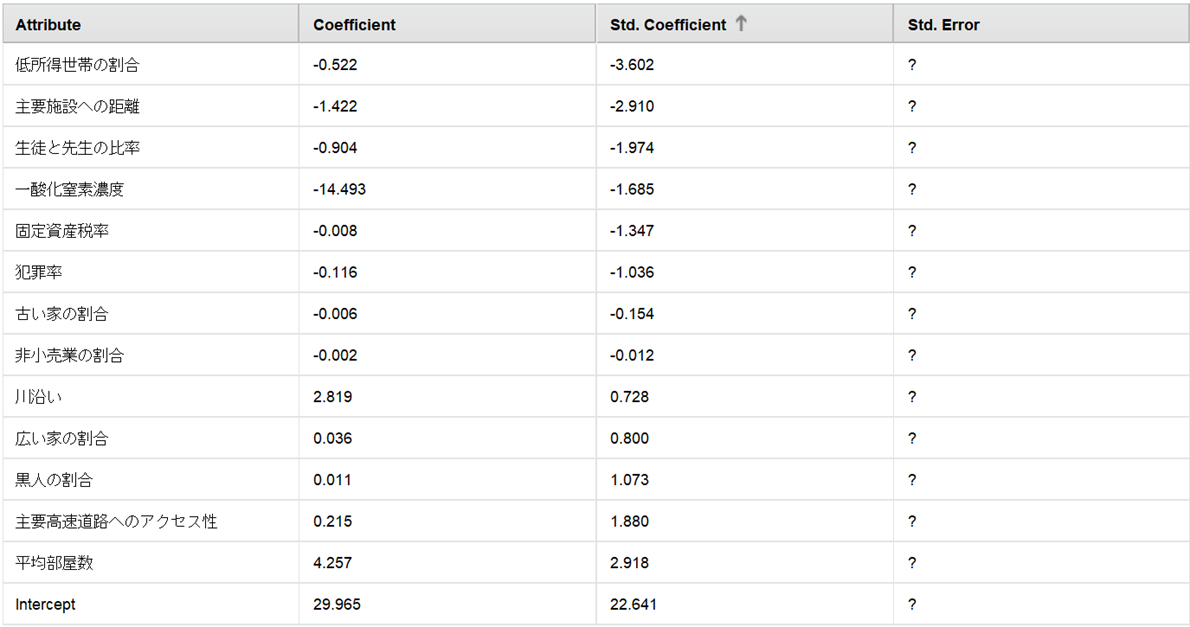
・GLMモデルの回帰係数
Coefficient(係数)は、説明変数が1単位変化したときに予測結果に与える影響を表します。ただし、説明変数間でスケールが異なる場合、それぞれの説明変数が1単位変化した効果を見ても正しい比較が難しくなります。そこで、説明変数の単位を統一して回帰係数の比較からスケールの影響を取り除く手法として標準化があります。標準化された回帰係数がStd.Coefficient(標準係数)となります。下表のStd.Coefficientから、以下のことが分かります。
– 低所得世帯の割合が1単位増加すると住宅価格がマイナス3.602変化する
– 主要施設への距離が1単位増加すると住宅価格がマイナス2.910変化する
– 平均部屋数が1単位増加すると住宅価格がプラス2.918変化する
– 主要高速道路へのアクセス性が1単位増加すると住宅価格がプラス1.880変化する
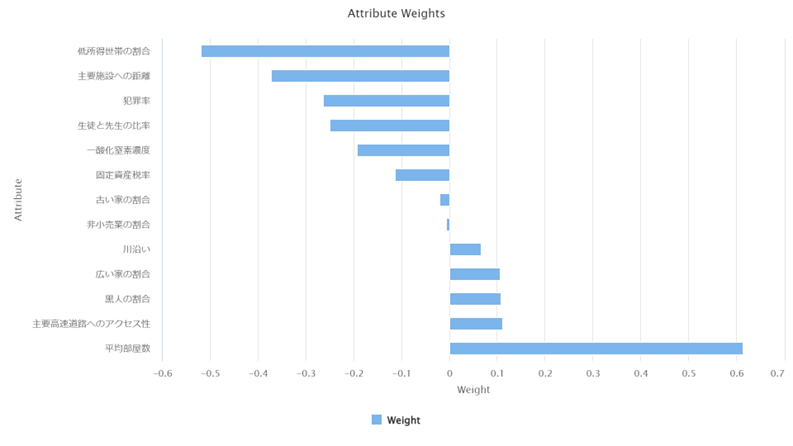
3-3. 貢献度の可視化
・全体平均
各説明変数の平均的な貢献度が可視化されました。可視化から以下のことが分かります。
– 低所得者の割合、犯罪率のマイナスの貢献度が大きい
– 平均部屋数、主要高速道路へのアクセス性のプラス貢献度が大きい
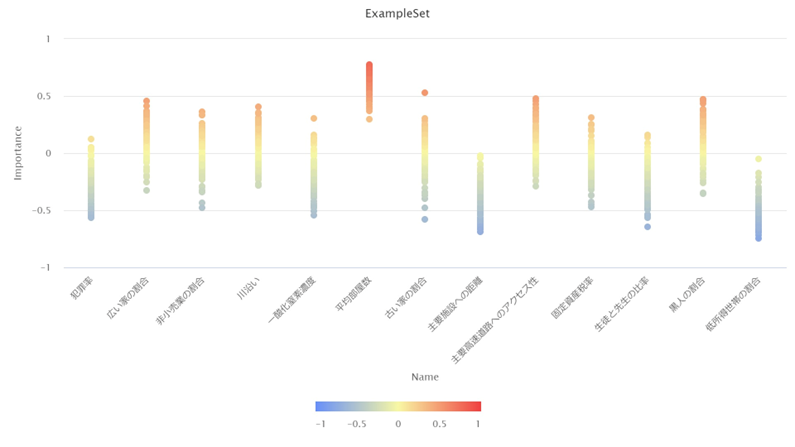
・各説明変数の貢献度の分布
各説明変数の貢献度の分布が可視化されました。点の色が赤いほど貢献度の値が大きく、点の色が青いほど貢献度の値が小さいことを表しています。
平均値では分らなかったことを理解することができます。可視化から以下のことが分かります。
– 低所得世帯の割合がマイナス0.05~マイナス0.75付近に分布している
– 低所得世帯の割合が予測にマイナスの貢献をしている
– 平均部屋数がプラス0.3~プラス0.8付近に固まっている
– 平均部屋数が多いほど予測にプラスの貢献をしている
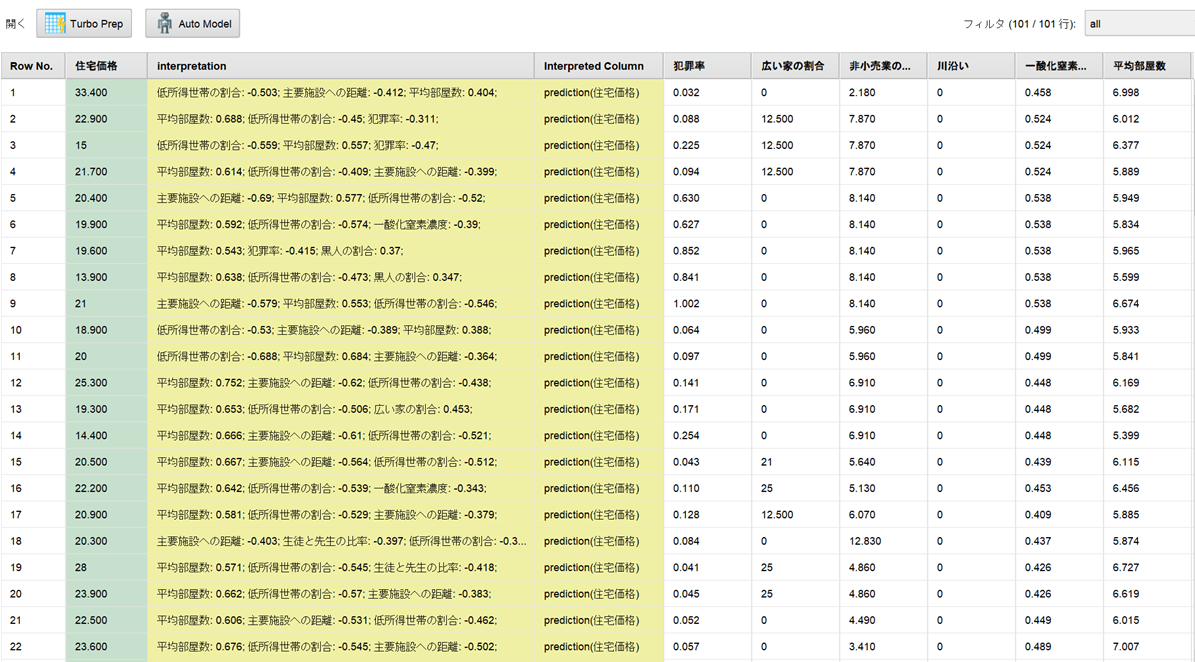
・個別インスタンスの貢献度
個別インスタンスの予測に対する各説明変数の貢献度が値の大きい順に上位3個まで(変更可能)可視化されました。可視化から以下のことが分かります。
– Row No 1:低所得世帯の割合が1単位変化すると住宅価格が平均でマイナス0.503変化する可能性がある
– Row No 2:平均部屋数が1単位変化すると住宅価格が平均でプラス0.688変化する可能性がある
ExcelとRapidMinerの比較
ExcelとRapidMinerのデータ分析機能の比較表をまとめました。
| Excel | RapidMiner | |
|---|---|---|
| 操作性 | ・データ分析ツールの回帰分析を使って行う ・Excel上で目的変数と説明変数の範囲指定が必要 ・予測を行う場合、回帰係数と切片から回帰式を作成、または、TREND関数を利用する | ・GUIでノンプログラミングでの分析が可能 ・有償版では、TurboPrerpとAutoModelを利用して、より簡単にデータ加工、モデル作成・評価が可能 |
| 分析 アルゴリズム | 回帰分析 | ・一般化線形モデル(GLM) ・ロジスティック回帰 ・Deep Learning ・Random Forest ・GVDT (Gradient Boosting Decision Tree)などPythonコードによる独自アルゴリズムの組込可能 |
| 説明性 | 回帰係数、t値 | 全体平均、説明変数毎の分布、個別インスタンス毎に貢献度を豊富なグラフで可視化できる 貢献度の算出にSHAP、LIMEが利用可能 |
| ドキュメント | ・日本語のドキュメント ・ネット上に多くのコンテンツが存在する | ・英語のドキュメント(一部日本語あり) ・RapidMiner Community(英語) |
| その他 | ・説明変数は最大16個まで ・カテゴリー変数はIF文等でダミー変数化する | カテゴリー変数のダミー変数化、標準化、サンプリングなどデータ下降に必要な機能が用意されている |
まとめ
- .Excelの分析ツールの「回帰分析」を使って「数値予測」と「要因分析」が可能です
- 説明変数が最大16個までという制限があるため、実際の業務で利用することが難しい
- 説明変数の目的変数に対する影響度は、回帰係数やt値で判断します(全体平均のみ)
- Rapidminerを使えば、17個以上の説明変数を持ったデータの「数値予測」と「要因分析」を簡単なマウス操作で実現できます。説明変数の目的変数に対する影響度を、全体平均、説明変数毎の分布、個別インスタンス毎に可視化して要因分析の深堀りが可能です
製品や関連資料の紹介
機械学習プラットフォーム RapidMinerについては【こちら】
参考資料1. Rapidminer Marketplace Interpretation【RapidMiner Marketplace】
参考資料2.「7日間集中講義! Excel 回帰分析入門:ツールで拡がるデータ解析&要因分析(米谷 学著)」(オーム社)
参考資料3.「機械学習を解釈する技術〜予測力と説明力を両立する実践テクニック(森下 光之助著)」(技術評論社)

著者プロフィール

SoEアーキテクト課 長井伸次
AIデータ分析事業のデータエンジニア・Business Data Scienceエバンジェリスト
1990年代にSybaseとSASを利用した銀行系アプリの設計・開発・保守を担当、以来Oracleを利用した業務アプリケーションの設計、開発、保守、パフォーマンス改善担当など、DBスペシャリストとして様々な業務アプリケーションのプロジェクトに参画。その後、RapidMinerによるAIの民主化と導入支援プロジェクトを担当。
無料個別相談会を開催しています!
・法人審査でお困りの方
・データを使った方法に興味がある方
・実際にデモを見たい方
・詳細な説明を聞きたい方
などを対象に、無料の個別相談会を開催します。
どのような些細なことでもお気軽にお問い合わせください。
お問い合わせはこちら>
