はじめに
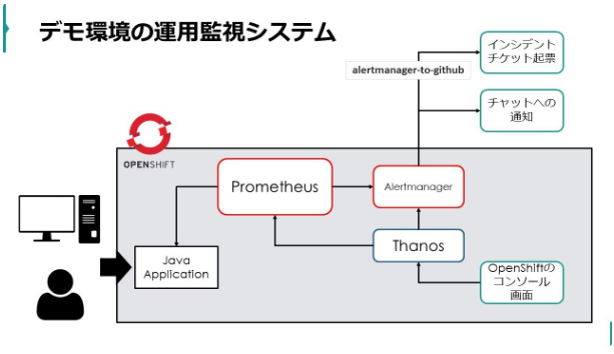
こんにちは、NADPの原木と申します。今回はOpenShift4.6でGAになった”Monitoring for user-defined projects”について、OpenShiftの運用監視システムの概要を交えながら説明したいと思います。
技術背景
CRD(Custom Resource Definition)
Kubernetes上のOperatorの設定など、KubernetesのデフォルトのAPIでは業務要件を満たさない場合、カスタムリソースと呼ばれる拡張機能を用いてユーザーが独自にAPIを定義することができます。
そこで登場するのがCRDです。CRDを用いると、カスタムリソースを簡単に追加することができます。
OpenShiftはOperatorの導入によりクラスタのバージョン管理やモニタリングスタックなどいろいろな機能を自動化しているため、OpenShiftの運用ではCRDによる調整作業をよく行います。
Prometheus
Prometheusはメトリクスベースのモニタリングシステムです。対象のサービスから運用監視に必要な情報を取得し、統計処理を行った上で人がわかりやすい形に集計することができます。
現在、数多くのManagedなモニタリングサービスやプロダクトがありますが、その中でPrometheusはプロジェクト当初からKubernetesなどの分散システムとの親和性を考えて開発が行われてきました。その一つがServiceDiscoveryと呼ばれる、サービスの自動捕捉機能です。
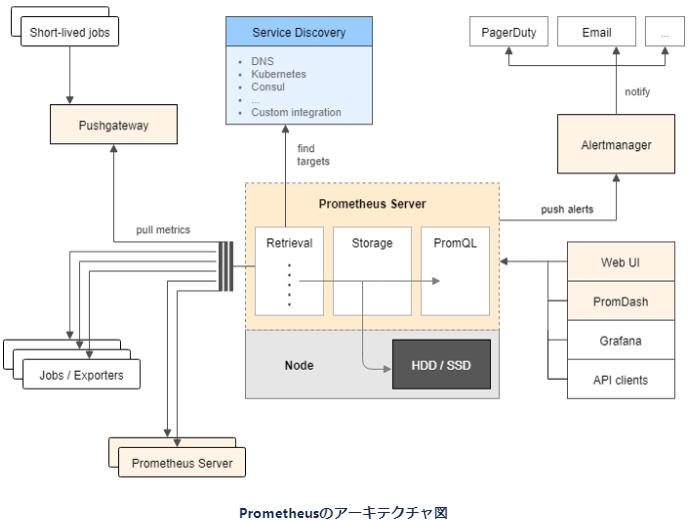
✽ 上記アーキテクチャ図は2015年10月にリリースされたv0.16.0のREADMEで書き直されたアーキテクチャ図です。それから五年間、Prometheusは現在もメトリクスを格納する時系列DBの改良など盛んに開発が続けられていますが、基本的な設計は変わっていません。Prometheusのアーキテクチャデザインが優れている証左だと存じます。
PrometheusはPull型のアプローチをとっており、Prometheus側からメトリクス情報を取得するため、対象のサービスが今どこにあるのかを知る必要があります。例えば、Kubernetes上なら、Pod名やService名にあたります。Service Discovery機能は、KubernetesAPIに問い合わせをすることで、自動的に情報を取得する機能です。
Prometheus Operator
Prometheus Operatorは、Kubernetesのカスタムリソースを使用して、Prometheus、Alertmanager、および関連するモニタリングのコンポーネントのデプロイ及び構成を簡素化します。
OpenShiftにはPrometheus Opetatorとしてcoreos社によるPrometheus Operatorがデフォルトの運用監視機能として入っています(過去には別のベンダーが実装したPrometheus Operatorもありました)。
Prometheus OperatorにはPrometheusにはない便利な機能がいくつかあります。代表的な機能の一つにServiceMonitorと呼ばれる監視対象のサービスをKuibernetesのラベルに従って自動的に検出する機能があります。先ほど紹介したService Discovery機能を発展させた形ですが、Kubernetes/OpenShift上の運用監視のための手間が減る強力な機能なので、後の章で具体的な使い方を説明したいと思います。
Thanos
ThanosはPrometheusのメトリクスを長期保存し、高可用性をもたらすためのツールです。
Prometheusのメリットは、クラウドネイティブなService discovery機能やメトリクス情報を時系列処理するために効率的に圧縮し、処理できることです。一方で、そのデータを数か月以上永続的に保存したり、違うクラスタをまたいでメトリクスを取得したいといったマルチクラスタの要望に応えるには、決して不可能ではありませんが構造上難しいデメリットもあります。
この辺りの課題を解決するために、Prometheusの機能を拡張させるプロダクトとしてThanosは生まれました。Prometheusからデータを透過的に扱うことができ、スケールアウトが簡単にできる仕組みであるThanosは、Prometheusと必ずセットで使われています。より詳細の経緯を知りたい場合、Thanosのオリジナルの開発元であるImprobable社のブログをご覧ください。(参照元のURLは現在利用できなくなっております。)
元々はクラウドのゲームプラットフォームを行っているImprobable社が自社の業務要件を満たすために開発を行い、その後OSSとして公開されました。現在ではImprobable社の人はメンテナーを離れ、Red Hat社をはじめとする様々なエンジニアにより、開発、保守されています。
OpenShiftにデフォルトで入っている運用監視システム
OpenShiftには、デフォルトの運用監視システムとしてPrometheusとGrafanaダッシュボードがデフォルトで提供されています。ただし、従来、それらはOpenShiftを構成するコンポーネントやVMの監視機能のためのものであり、OpenShift上にユーザーがデプロイしたサービスに関しては別途、運用監視システムを準備する必要がありました。
OpenShiftでクラスタを監視しているのと同じ仕組みで自分たちのサービスを監視したい。
運用監視システムにVMからコンテナ上のアプリケーションまで一貫性を持たせたい。
そういった要望に応える形でずっとtech previewとして評価機能にあったとある機能がこの度、OpenShift4.6でGA(一般提供段階)になりました。
それが、”Monitoring for user-defined project” です。
OpenShift4.6のリリースノートから機能説明を引用します。
With this new feature, you can perform the following tasks:
この新しい機能で下記のタスクを行うことができます。
*Enable and configure monitoring for user-defined projects
ユーザー定義のプロジェクト(OpenShift上にユーザーがデプロイしたサービスのこと)に対する
モニタリングの実行、調整が可能になります。
*Create recording and alerting rules that use metrics from your own pods and services
ユーザー自身のポッドやサービスのメトリクスを使用して、記録とアラートのルールを
作成することが可能になります。
*Access metrics and information about alerts through a single, multi-tenant interface
単一、複数のテナントインターフェースを通じて
アラートに関するメトリクスや情報にアクセスできます。
(訳補:最近のOpenShiftのトレンドはクラスタの安定稼働を実現する上で欠かせない、マルチクラウド、マルチクラスタによる冗長化構成への対応です。Advanced Cluster Management toolをはじめとして、複数のクラスタ環境の管理を簡単にできるように機能拡張が進められています。運用監視においても、Thanos Querierというサービスを用いて重複するメトリクスを削除、集約することでマルチクラスタ環境下でも監視を容易に行えるようになりました。このブログではそこまで深く話ができないので詳細はBanzai Cloud社のMulti cluster monitoring with Thanosをご覧ください)
*Cross-correlate the metrics for user-defined projects with platform metrics
ユーザー定義のプロジェクトのメトリクスをプラットフォームのメトリクスを相互相関させる
ユーザー定義のプロジェクトのメトリクスとプラットフォームのメトリクスをまとめると、下に記した全体図になります。OpenShift4.6のマニュアルより参照します。
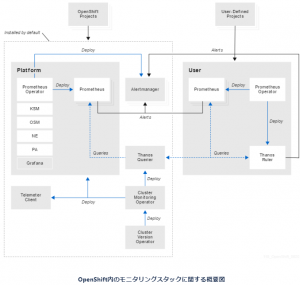
一見、ユーザー定義のプロジェクトを監視するために多くのコンポーネントの設定が必要に見えます。
しかし、ユーザーが定義したプロジェクトの監視は右半分、しかもその中のPrometheus OperatorのCRDさえ書けば後はOperatorが自動で行ってくれるため、
実は最低限動かすために必要な設定は多くありません。
# OpenShiftの監視スタックに関するCRDの一覧 $ oc get crd -o name | grep .monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/ptometheusrules.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com customresourcedefinition.apiextensions.k8s.io/thanosrules.monitoring.coreos.com
この中で最低限必要なCRD、及び関連情報の設定について具体例を交えて紹介します。
ServiceMonitor
ServiceMonitorはKubernetesのServiceリソースからメトリクス対象のサービスを選択するために用いられます。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: handsondemo-app-monitor
namespace: handson-demo
spec:
endpoints: ①
- interval: 30s
path: /metrics
port: app-port
scheme: http
selector: ②
matchLabels:
services: app-svc
namespaceSelector:③
matchNames:
- ns1
- ns2
---
apiVersion: v1
kind: Service
metadata:
name: app-svc
labels:
services: app-svc
spec:
ports:
- name: app-port
port: 8080
targetPort: 8080
selector:
app: app
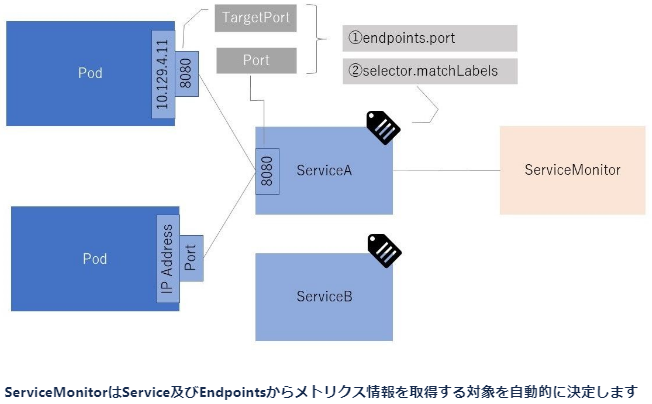
①エンドポイントの設定
メトリクスを取得するために必要なエンドポイントの設定です。サンプルでは、app-svcのapp-portに対して30秒おきにメトリクス情報を取得するためにリクエストを送るように設定しています。
②ラベルの設定
指定されたラベルが振られたKubernetesの Serviceリソースを選択します。サンプルでは、 services: app-svcというラベルが振られた app-svcからメトリクス情報を取得します。
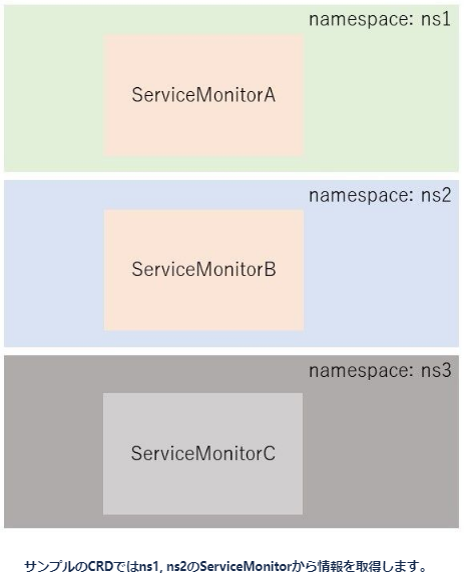
③名前空間の設定
prometheus-operatorは何も設定しない場合、operatorと同じnamespaceからしかメトリクス情報を取得できません。
一般的に監視したいサービスはprometheus-operatorをデプロイしたnamespaceとは違うnamespaceにデプロイしていると思いますが、その場合、追加の設定が必要です。
- namespaceSelectorによる対象のnamespaceの設定
- 対象のnamespaceを羅列します
- namespaceから情報を読み取るためのRBACの設定
- namespaceへのアクセス権限の設定です。取り扱いには注意が必要なので、Operator Lifecycle ManagerのScoped Operatorに任せると負担が軽減します。
また、逆にnamespaceで制限をかけたくない場合も明示的に設定する必要があります。
namespaceSelector: any:true
PrometheusRulers
PrometheusRule/ThanosRuleは異常検知用のクエリを設定するためのCRDです。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: handsondemo-app-alert
namespace: handson-demo
spec:
groups:
- name: ExcessiveUsage
rules:
- alert: ExcessiveUsage
annotations:
summary: 80%のリクエストが返るまでに200ms以上かかってます。このままではサービスレベルを維持できません。
expr: histogram_quantile(0.80, sum(rate(getAddressNameNoCache_seconds_bucket[30s]))
by (le)) > 0.2
for: 10s
labels:
namespace: handson-demo
severity: critical
usage: handson
histogram_quantile というPrometheusの統計用メソッドによりクォンタイルを算出します。具体的にはレイテンシーを早い順に並べたときに上位から80%にあたるリクエストが0.2秒以上かかっていたらサービスレベルが下がっているとみなして”ExcessiveUsage”というalertを発行し、Alertmanagerに警告を依頼します。
AlertmanagerのReceiver
AlertmanagerのReceiverは警報を受け取った後、どういう方法でユーザーに警告を出すか、設定する役割があります。これはCRDではなく、alertmanagerが参照するsecretファイルに直接configを設定します。
サンプルでは、
- デフォルトの警告としてSlackに通知するNotifySlack
- リクエストが多すぎるExcessiveUsageという異常の場合に、OpenShift上のalertmanager-to-githubにwebhookで通知するNotifyGHWebhook
を設定しています。
このconfigファイルのデプロイ方法など、詳細を知りたい場合は下記のマニュアルをご覧ください。
global:
resolve_timeout: 5m
receivers:
- name: NotifySlack
slack_configs:
- channel: openshift-alert
api_url: >-
https://hooks.slack.com/services/XXXX/YYYYY
- name: NotifyGHWebhook
webhook_configs:
- url: http://alertmanager-to-github.handson-demo:8080/v1/webhook?owner=nelco-abm&repo=openshift-handson-apps-addresscode
send_resolved: false
max_alerts: 100000000000000000
route:
# ハンズオン用に死ぬほど重い値をいれてます
group_interval: 1s
group_wait: 1s
receiver: NotifySlack
repeat_interval: 12h
routes:
- receiver: NotifyGHWebhook
match:
alertname: ExcessiveUsage
ConfigMap: cluster-monitoring-config
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
enableUserWorkload: true ①
これもCRDではありませんが、必要なconfigです。
有効にすると下記の通り、CRDのPrometheusリソースがuser-workloadという名前で保存されます。
$ oc get Prometheus -A NAMESPACE NAME VERSION REPLICAS AGE openshift-monitoring k8s v2.20.0 2 180d openshift-user-workload-monitoring user-workload v2.20.0 2 44d
このPrometheusリソースはOpenShift上に入っているcluster-monitoring-operator機能によって、自動的に作成されます。cluster-motoring-configの設定にはtaints/tolerationの設定などOperatorのPodを制御するための機能しかありません。このPrometheusリソースを後から修正したい(例えばスクレイピングの設定を独自に入れたい)と思ってもcluster-monitoring-operatorで自動的に修復されてしまうので注意が必要です。
OpenShiftの運用監視システムを使ってJavaアプリケーションのレイテンシーを元に異常検知する
OpenShiftの運用監視システム及び独自に組み入れたPFNさんのAlertmanagerToGitHubというツールを用いてモニタリングの指標としてOpenShift上で動かしているJavaアプリケーションであるQuarkusのレイテンシ―を測定します。
レイテンシーとは
レイテンシ―はシステムがサービスに対してリクエストを処理するためにかかる時間のことです。パフォーマンス劣化を検知するために、GoogleのGolden Methodの一つにも採用されている重要な指標です。
レイテンシーの計測方法は処理するためにかかった時間を測るだけなので単純です。しかし、計測方法のお手軽さとは裏腹に、どういう時にパフォーマンス劣化が生じているか検知するための方法は少々厄介です。なぜならレイテンシ―の値はばらつきがあるからです。
マイクロサービスアーキテクチャを採用している場合など特に顕著ですが、今ぱっと思いつく限りでも下記の要素により簡単に早くも遅くもなります。
- ネットワークの輻輳(データ量が多すぎてネットワークが詰まった状態)
- 分散トレーシングやスタックトレーシングのログをうっかり標準出力していたことによる処理遅延
- フルGarbage Collectionの実行による一時停止
- VMのストレージのIOPSの制限を超過したことによる不安定化 (このIssueは非常に示唆に富んでいるのでMicrosoftのAzureKubernetesServicesを使用したことがない方でもぜひ一度はご覧ください。)
等々…
したがって、レイテンシ―によるモニタリングは単純に○○以上はエラーとするといったしきい値ではなく、パーセンタイルによるチェックが一般的に行われています。
例えば、100回リクエストを送信して処理にかかった時間を早い順番に並べてみたとします。この時、80%パーセンタイルとは上位から80番目に遅かったリクエストの時間を指します。下記の図では300msにあたります。
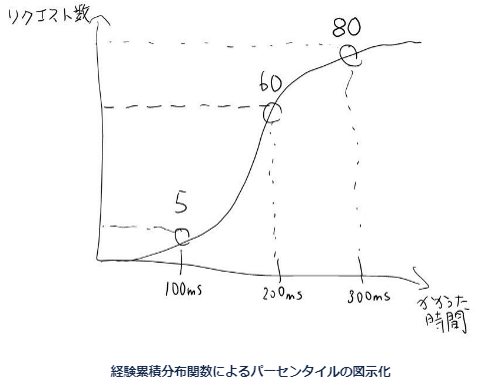
経験累積分布関数によるパーセンタイルの図示化
レイテンシーをパーセンタイルでモニタリングするメリットは、極々稀にある異常値(極端に遅い場合)に強いことです。
もちろん、異常系を見逃せというわけではありません。単純に向き不向きの問題です。
パーセンタイルはサービス全体を見まわしたときに正常であることを確認するのに向いており、個々の異常系は例外系のログなどまた別の適した監視機能で行ったほうがより効率よく運用を回せます。
パーセンタイルは便利ではありますが、アプリケーションで処理にかかった時間を一つのリクエストごとに素直に監視システムに送ると、送信するデータ量が多すぎてネットワーク回線が爆発します。したがって、パーセンタイルで把握するために必要なbucket情報をあらかじめ測定し、bucket情報ごとにカウントとしたリクエスト数の累計情報を送る方法が一般的です。prometheusではHistogramとして方法が紹介されています。 @ocadarumaさんのhistogram_quantileはどのようにquantileを計算しているかにより詳しい解説が掲載されているのでご覧ください。
上記の図で、下のかかった時間をご覧ください。100ms, 200ms, 300msと100msごとにリクエスト数を集計していますが、この間隔がbucketです。bucketの区切れ目ごとに、それまでの累計を出力することでパーセンタイル集計に必要なメトリクス情報を提供しています。
わかりやすくbucketの切れ目が一定間隔にしていますが、実際はリクエストにかかった時間の偏りなどをもとにいい感じの計算を行っています。詳細はLINEさんのレイテンシーを計算する技術の話が非常に詳しいのでご一読ください。
レイテンシーをメトリクスとしてPrometheusに送るまで
今回、メソッドごとにかかった処理時間をOpenShift上のPrometheusに送りたいと思います。
JFR Event Streamingについて というブログで、JFR Event Streamingを用いてメソッドごとの処理時間を簡単に算出する方法を紹介いたしました。QuarkusのMicrometerライブラリを使って、実際に計測した時間をPrometheus側で受け取れるようにするには下記のように実装します。
// JFRのeventの処理時間合計をMicrometerのメトリクスとして出力する
Timer timer = Timer.builder(name).description("1ms~15sのHistogramを作成する")
.publishPercentileHistogram() // create percentile histogram
.minimumExpectedValue(Duration.ofMillis(1)) // 最低1ms
.maximumExpectedValue(Duration.ofSeconds(15000)) // 最悪の場合、15秒
.tags("method", method).register(this.registry);
timer.record(event.getDuration().toNanos(), TimeUnit.NANOSECONDS);
実際は下記のような情報をメトリクスとして送られます(正確にはPrometheus側からのリクエストに応じてメトリクス情報を返します)。
getAddressNameNoCache_seconds_bucket{method="getAddressNameNoCache",le="0.100",} 5
getAddressNameNoCache_seconds_bucket{method="getAddressNameNoCache",le="0.200",} 60
getAddressNameNoCache_seconds_bucket{method="getAddressNameNoCache",le="0.300",} 80
getAddressNameNoCache_seconds_bucket{method="getAddressNameNoCache",le="+Inf",} 100
getAddressNameNoCache_seconds_bucketはメトリクスの名前です。
中括弧{}で括られた部分はラベルと呼ばれています。
Prometheusはこのラベルに基づきメトリクス情報を仕分けします。
今回は method と le ラベルがついています。
leは less than or equal to (未満もしくは同じ)を意味しており、
処理にかかった時間について「0.1秒以下、0.2秒以下、0.3秒以下、無限」それぞれを表しています。
最後の数字はリクエスト数です。累計なので一番最後の数値は必ずリクエスト数の合計になります。
PrometheusからThanosを通じてAlertManagerが発火するまで
冒頭で、紹介した異常検知用のクエリを設定するためのCRDであるPrometheusRuleを設定することで、AlertManagerが発火します。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: handsondemo-app-alert
namespace: handson-demo
spec:
groups:
- name: ExcessiveUsage
rules:
- alert: ExcessiveUsage
annotations:
summary: 80%のリクエストが返るまでに200ms以上かかってます。このままではサービスレベルを維持できません。
expr: histogram_quantile(0.80, sum(rate(getAddressNameNoCache_seconds_bucket[30s]))
by (le)) > 0.2
for: 10s
labels:
namespace: handson-demo
severity: critical
usage: handson
AlertManagerToGitHubを通じてGitHubに警告を出力する
PFNさんのalertmanager-to-githubを使用すると、Alertmanagerの警告の内容をGitHub上にIssueチケットとして作成することができます。
- alertmanager側でwebhookでalertmanager-to-githubを呼び出しているところ
global:
resolve_timeout: 5m
receivers:
- name: NotifyGHWebhook
webhook_configs:
- url: http://alertmanager-to-github.handson-demo:8080/v1/webhook?owner=nelco-abm&repo=openshift-handson-apps-addresscode
send_resolved: false
max_alerts: 100000000000000000
route:
group_interval: 1s
group_wait: 1s
receiver: NotifySlack
repeat_interval: 12h
routes:
- receiver: NotifyGHWebhook
match:
alertname: ExcessiveUsage
- alertmanager-to-githubのマニフェストファイル
---
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "10"
name: alertmanager-to-github
namespace: handson-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/name: alertmanager-to-github
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/name: alertmanager-to-github
spec:
containers:
- env:
# ラベルを必ず設定しないとIssue作成時にエラーになります
- name: ATG_LABELS
value: alerts
- name: ATG_LISTEN
value: :8080
# githubのtokenはsecretより読み込みます
envFrom:
- secretRef:
name: env-secrets
image: quay.io/pfnet-alertmanager-to-github/alertmanager-to-github:v0.0.1
imagePullPolicy: IfNotPresent
name: main
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: 500m
memory: 500Mi
requests:
cpu: 1m
memory: 10Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
terminationGracePeriodSeconds: 30
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager-to-github
namespace: handson-demo
spec:
clusterIP: 172.30.5.10
ports:
- port: 8080
selector:
app.kubernetes.io/name: alertmanager-to-github
下記のように、GitHubのIssueチケットとして起票されるので、そのまま対応作業に移ることができます。

感想
OpenShift4.6の ”Monitoring for user-defined projects”により、メトリクス情報の収集について、OpenShiftのクラスタから上で動いているウェブサービスに至るまで、一貫した仕組みで行うことができるようになりました。
今回はメトリクス情報の収集をレイテンシーなど障害を早期検知するために使用しましたが、Kubernetesの現場ではメトリクス情報に合わせてサーバーやアプリケーションの増減を自動的に行うHPA(Horizontal Pod Autoscale)などにも応用されています。
これを機にますます、OpenShiftはプラットフォームとして成熟していくことでしょう。
記事担当者:アプリケーション企画開発部 原木
投稿日:2020/12/03
